





Baidu DeepVoice: chiński Google ujawnia swój generator mowy
WaveNet od Google to nie jedyny generator mowy wykorzystujący głębokie uczenie maszynowe. Konkurencję o ogromnym potencjale ogłosił właśnie chiński gigant Baidu. Jakie możliwości ma oferować jego DeepVoice?


Sztuczna inteligencja według Baidu
Całkiem sporo wiadomo już o projektach Google, wśród których nie brakuje tych wykorzystujących uczenie maszynowe. Znalazł się wśród nich m.in. DeepMind, już dziś wygrywający z ludźmi w grach wideo. Technologia trafiła także do Google Translate, gdzie demonstruje bezprecedensową prędkość w rozumieniu kolejnych języków.
Jednym z najnowszych zastosowań Deepmind jest projekt WaveNet, w drodze głębokiego uczenia analizujący fale dźwiękowe wypowiedzi, porównujący je z zapisem tekstu, a finalnie generujący inne zdania przy zachowaniu identycznego brzmienia głosu. Jego słabością jest ogromne zapotrzebowanie na moc obliczeniową, która uniemożliwia pracę w czasie rzeczywistym.
Wyzwanie podjął chiński gigant Baidu, od 2013 roku pracujący w Dolinie Krzemowej nad sztuczną inteligencją. Jego działalność koncentruje się na wielu dziedzinach, wśród których znalazły się m.in. autonomiczne samochody oraz system generowania mowy: DeepVoice. Rezultaty prac nad tym ostatnim inżynierowie firmy właśnie ogłosili publicznie.

Mowa rozbita na czynniki pierwsze
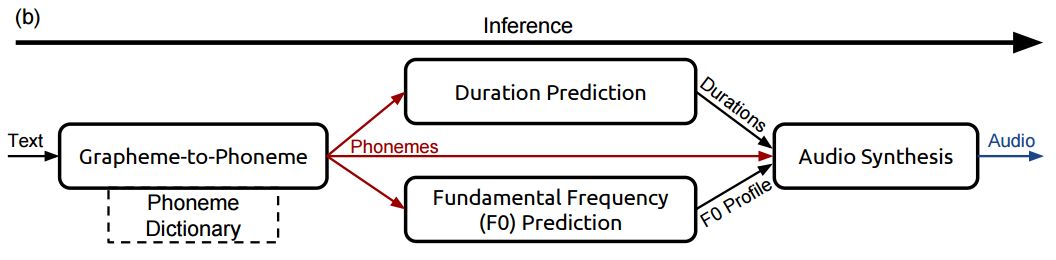
Działanie DeepVoice polega na rozłożeniu tekstu na pojedyncze grafemy (najmniejsza jednostka pisma), a następnie przełożeniu na fonemy (najmniejsza jednostka mowy). Dopiero z tych ostatnich jest konstruowana wypowiedź, w której zmieniając akcent i długość odtwarzania fonemów można także zawrzeć emocje.
Deklarowane możliwości Deepvoice robią wrażenie: uczy się on mowy w zaledwie kilka godzin. Wkład człowieka jest ograniczony do minimum bądź zbędny, a wypowiedź jest generowana w czasie rzeczywistym.
Zapotrzebowanie na moc obliczeniową ograniczono względem konkurencyjnego WaveNet, choć wciąż jest ona dość spora. Inżynierowie za cel przyjęli częstotliwość próbkowania ok. 48 kHz, co daje komputerowi 20 µs na wygenerowanie każdego dźwięku. Jednocześnie pracuje przy tym kilka warstw co każdej z nich daje czas 1,5 µs na wykonanie zadania.
Obiecujące rezultaty
Wygenerowane przez DeepVoice nagrania trafiły już na platformę crowdsourcingową Amazona, Mechanical Turk. Otrzymały od respondentów naprawdę wysoką ocenę, co na tym etapie świetnie rokuje innowacyjnemu projektowi. Publicznie nie zaprezentowano jednak żadnych próbek dokonań chińskiego zespołu inżynierów.
Na konkurencji najbardziej zyskuje konsument i nie inaczej będzie w przypadku rywalizacji Google’a z Baidu. Do implementacji technologii w nawigacjach czy sekretarkach telefonicznych jeszcze długa droga, jednak jakość jaką ma przynieść jest z pewnością warta oczekiwania. Alexa, Cortana i im podobne asystentki w przyszłości zabrzmią nie mniej przekonująco od nas samych.












